Agent智能体技术简介
Agent智能体技术简介
Agent智能体技术简介
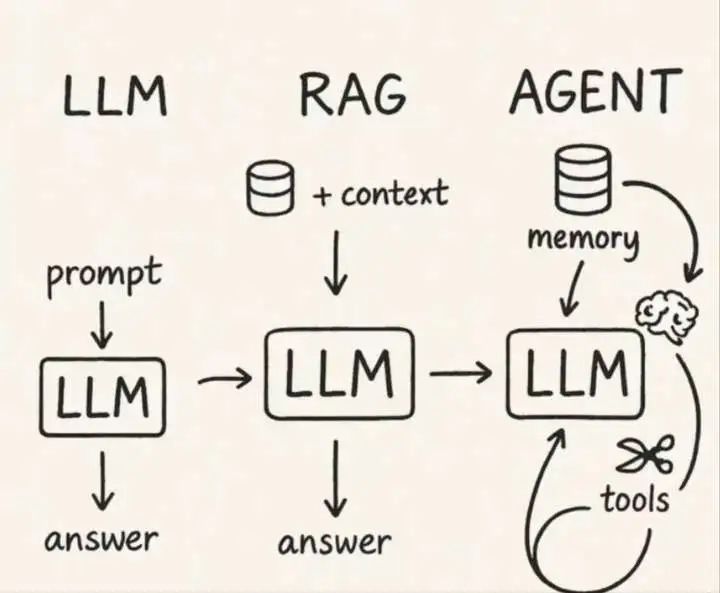
什么是智能体
智能体本身不内置小模型,智能体是一个程序框架:
1
智能体 = 程序逻辑 + 大模型调用 + 工具集成 + 记忆管理
智能体内部架构
1
2
3
4
5
6
7
8
9
10
11
12
13
┌─────────────────────────────────────────────────────────────┐
│ xxxAgent │
├─────────────────────────────────────────────────────────────┤
│ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────┐ │
│ │ A2A Protocol │ │ MCP Client │ │ OpenAI SDK │ │
│ │ (Agent调用) │ │ (工具调用) │ │ (大模型) │ │
│ └─────────────────┘ └─────────────────┘ └─────────────┘ │
├─────────────────────────────────────────────────────────────┤
│ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────┐ │
│ │ 系统提示词 │ │ 业务逻辑 │ │ 记忆管理 │ │
│ │ (角色定义) │ │ (处理流程) │ │ (会话) │ │
│ └─────────────────┘ └─────────────────┘ └─────────────┘ │
└─────────────────────────────────────────────────────────────┘
在一个智能体内部:
- 可以调用其他agent,使用A2A协议;
- 可以调用mcp服务,内嵌有mcp客户端;
- 可以调用大模型,包含有openai sdk。
为什么需要多智能体
单智能体的缺陷
- 能力边界问题
- 知识范围:单个智能体很难同时精通多个专业领域
- 任务复杂度:复杂任务需要分解,单个智能体容易”迷失方向”
- 记忆容量:长对话中容易忘记早期的重要信息
- 角色冲突
- 决策偏差:同一个智能体既要分析又要决策,容易产生偏见
- 责任分散:难以区分是分析错误还是决策错误
多智能体的优势
- 专业分工
1 2 3 4
分析智能体:负责数据分析和问题理解 决策智能体:负责制定解决方案和行动计划 执行智能体:负责具体任务执行 监督智能体:负责质量检查和错误纠正
- 协作增效
- 互补性:不同智能体各有所长,相互补充
- 并行处理:可以同时处理多个子任务
- 质量提升:多角度分析,减少盲点
- 错误容错
- 冗余检查:多个智能体可以交叉验证结果
- 故障隔离:某个智能体出错不会影响整体
多个智能体之间的不同
每个Agent,都设置有不同的系统提示词和绑定不同的mcp服务,来体现其专注于某一领域和专业性,方便和通用大模型对接。
- 角色扮演:通过不同的系统提示词定义专业身份
- 工具配置:使用不同的MCP服务来扩展能力
- 业务逻辑:针对不同领域设计专门的处理流程
- 协作方式:可以串行、并行或混合协作 这样设计的好处是:
- 专业化:每个Agent都专注于自己的领域
- 可扩展:可以轻松添加新的专业Agent
- 可维护:每个Agent的职责清晰,易于调试
- 可复用:Agent可以在不同场景下组合使用
智能体的会话管理
Agent每次调用模型时,需要根据历史对话内容,构建合适的上下文信息。
会话流程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// 伪代码示例
public class AIAgent {
public String processUserInput(String input, String sessionId) {
// 1. 获取历史对话
List<Message> history = messageService.getSessionHistory(sessionId);
// 2. 构建上下文
String context = buildContext(history);
// 3. 调用大模型
String response = llmService.generateResponse(input, context);
// 4. 存储对话
messageService.saveMessage(sessionId, "user", input);
messageService.saveMessage(sessionId, "assistant", response);
return response;
}
}
数据存储
- sessions表:存储会话信息(session_id, user_id, created_at, status)
- messages表:存储对话内容(id, session_id, role, content, timestamp)
- context表:存储上下文摘要(session_id, summary, key_points)
会话管理机制
1
2
3
4
1. 用户开始对话 → 创建新session_id
2. 每次对话 → 存储到messages表,关联session_id
3. 对话进行中 → 通过session_id查询历史对话
4. 对话结束 → 更新session状态,可选择保留或清理
记忆策略
1
2
3
短期记忆:当前会话的所有对话内容
长期记忆:关键信息提取、摘要存储
检索增强:根据当前问题检索相关历史对话
构建上下文策略
上下文提交,不是每次都提交全部历史,这样会浪费token,也低效。
- 策略:固定轮数(简单)。只取最近几次的对话记录。
- 策略:智能摘要。使用大模型生成摘要,但会多调用一次大模型接口,且等待回复也会产生更多耗时。
- 策略:规则摘要。基于关键字等规则,提取对话内容的关键信息。
- 策略:多策略组合(推荐)。多种策略混合使用,同时合理使用缓存。
- 策略:向量检索(高级)。使用向量数据库,或者词嵌入模型 + 内存搜索,将历史对话转换为向量,检索最相关的内容。
智能体开发框架
- LangChain:包含基础LLM集成、提示词管理、工具集成、记忆管理、向量数据库、文档加载器。
- LangGraph:LangChain生态系统中的一个组件,专门用于构建有状态的AI应用。包含:状态图定义、节点间状态传递、工作流编排。
多智能体怎样协作
协调者
在任务开始的时候,有一个智能体专门用于任务分工和任务协调。职责有:
- 任务分析:理解用户需求的复杂性
- 任务分解:将复杂任务拆分为可执行的子任务
- 智能体分配:为每个子任务选择最合适的智能体
- 执行协调:管理智能体间的协作和结果整合
- 进度监控:跟踪整体执行进度
协作模式
- 串行协作(Sequential)
1
任务1 → 任务2 → 任务3 → 整合结果
- 并行协作(Parallel)
1 2 3
任务1 ─┐ 任务2 ─┼─→ 整合结果 任务3 ─┘
- 混合协作(Hybrid)
1 2 3
任务1 → 任务2 ─┐ 任务3 ──────────┼─→ 整合结果 任务4 ──────────┘
协作的关键问题
- 任务上下文传递:智能体之间应该可以共享上下文,获取前面智能体的分析结果。
- 分工进度监控:需要跟踪整体执行进度。
这些功能由A2A协议来规范。
智能体注册和发现
任务开始时的分工智能体,是怎样知道有哪些专业智能体的?是否有一个智能体中心来提供注册和服务发现?据了解目前是没有这种基础设施。
目前任务开始时的分工智能体,协作流程(串行或并行)以及使用哪些智能体,都是写死在代码里的。
工作流动态编排
一些框架如coze、dify、n8n等,实现了任务的动态编排,提供了状态管理和进度监控等功能,相当于替代了分工智能体这个角色。
本文由作者按照 CC BY 4.0 进行授权