RAG准确性提高案例
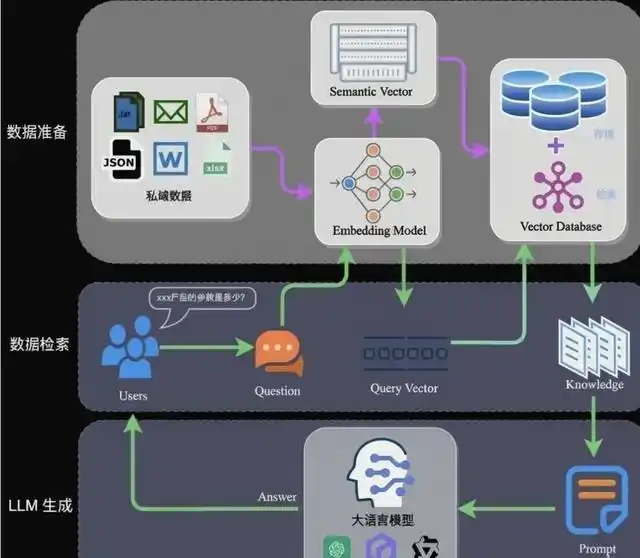
RAG准确性提高案例
面向不微调大模型、通过工程手段提升 RAG 准确率的落地复盘。场景为电力规程文档知识库问答,准确率从约 50% 提升至 88%,全程零模型微调。
- 原文作者:知乎用户
- 原文链接:https://www.zhihu.com/question/638730143/answer/2041228453932963535
- 原问题:如何在不微调的情况下提高 RAG 的准确性?
1. 背景与结论
作者团队做 RAG 落地一年多,在无 GPU 微调资源、无标注数据、无充裕时间的前提下,纯靠工程手段将准确率从 50% 提到 88%。
核心观点:
- 这些手段花钱少,多数代码量不大,但效果实打实;
- 别一上来就微调:先把工程优化做完,准确率仍达不到 80% 再考虑微调,大概率够用;
- RAG 的天花板在检索质量,不在大模型——检索不对,GPT-4 也没用(作者另文:为什么做了优化准确率仍上不去)。
2. 优化路径总览
按作者实践中的提升幅度与实施顺序归纳:
1
2
3
4
5
6
7
8
9
10
11
12
13
数据预处理(干净入库)
↓
结构化分块(按条款/章节,非硬切 512 字)
↓
Query 改写(口语 → 标准术语,召回率大幅提升)
↓
分库 / metadata 过滤(降噪声)
↓
Rerank(稳态 +7~8 个百分点)
↓
混合检索(向量 + BM25,锦上添花)
↓
Prompt 工程(压幻觉)
作者串联后的经验路径(各步贡献为作者项目内估算):
| 步骤 | 手段 | 效果(作者项目) |
|---|---|---|
| 1 | 数据预处理 | 约 +5% |
| 2 | 按文档结构分块 | 约 +15~20% |
| 3 | Query 改写 | 召回率约 35% → 80% |
| 4 | 分库召回 | top-5 命中率约 +15% |
| 5 | Rerank | 约 +7~8% |
| 6 | 混合检索 | 约 +3~4% |
| 7 | Prompt 工程 | 幻觉率约 15% → 5% 以下 |
3. 数据预处理:最不起眼,ROI 最高
场景:电力规程 PDF,质量参差不齐——排版好的、扫描件都有。
3.1 扫描件与 OCR
OCR 识别率 97% 听起来很高,但一个 512 字 chunk 里平均仍有约 15 个错字。错字向量化后成为噪声特征,检索时「噪声匹配噪声」,准确率难上去。
做法:
- 扫描 PDF 用高精度 OCR 重识别(作者用 PaddleOCR,效果优于 Adobe 自带 OCR);
- 识别后对关键页人工校验——不必全库校验,只校验含设备参数、操作步骤的页,约占总页数 20%。
3.2 表格
PDF 表格经 OCR 常乱序。Camelot 专门抽表格,结构化结果作为独立 chunk 入库;涉及参数查询的准确率「直接拉满」。
3.3 文档去重与版本
同一规程 2024 版与 2025 版同时在库,检索会召回两个版本的同一条款。加版本过滤,只取最新版,准确率再提升约 2 个百分点。
3.4 投入
主要是人力时间:约 1000 页文档库,预处理约 2~3 天。作者认为 ROI 最高。
4. 分块策略:硬切 vs 按结构切
512 字硬切 vs 按文档结构切,准确率相差 15~20 个百分点(作者实测)。
原因:电力规程按条款组织。第 X 条是一条完整操作流程。硬切可能把一条款切成两半——前半在 chunk A 讲「遇到 XX 应怎么做」,后半在 chunk B 讲「若做了 YY 会怎样」。只召回一半,大模型无法准确作答。
原则:
- 有章节标题 → 按标题切;
- 有条款号 → 按条款切(一条一个 chunk,完整、独立、自洽);
- 有操作步骤 → 按步骤切;
- 无结构纯文本 → 按段落切,段落过长再按句号切。
实测例(query:「变压器瓦斯保护动作后的处理流程」):
| 分块方式 | top-5 中相关条数 |
|---|---|
| 512 硬切 | 1 条 |
| 按条款切 | 4 条 |
chunk_size 从 128 调到 1024,影响远不如分块策略本身。与其死磕 chunk_size,不如先把文档按结构拆好。
5. 问题改写:召回率翻倍
用户问「保护老跳闸」,向量检索往往效果差——文档写的是「继电保护装置频繁动作」,存在术语 gap。
方案:用 7B 模型做 query 改写,把口语化、不完整的问题改写成 3 条标准术语检索 query。
Prompt 关键约束:「使用电力行业标准术语,补充隐含的技术细节。」无此约束时,改写过泛、过学术,效果反而更差。
效果例:
| 原始 query | 改写后(3 条示例) |
|---|---|
| 变压器嗡嗡响 | ① 变压器运行异常声响识别 ② 变压器正常运行声音特征 ③ 变压器异响原因分析及处理方法 |
召回率:35% → 80%。
模型选型:Qwen3-4B 即可,延迟 100ms 以内;35B 略好但延迟约 300ms,多数场景不值得。若已有 GPU 跑大模型,额外成本接近零。
6. 分库召回:砍掉噪声
做法:按文档类型建不同向量索引,共 6 类——运行规程、检修规程、调度规程、设备说明书、安全规范、项目技术文档。检索前用小模型判断问题类别,定向到对应库检索。
为何混库效果差:不同类型文档词汇重叠大(如「继电保护」在运行规程与检修规程都高频),混检时问运行问题却召回检修文档——语义相关但答非所问。
效果:top-5 命中率从约 60% 出头拉到接近 80%(作者表述为噪声大幅减少,而非准确率直接 +15%)。
替代方案:不分库,用 metadata filter(文档类型写入 Milvus / Qdrant 等 metadata,检索时过滤)。实现更简单,效果略逊于分库。
7. Rerank:最稳的一步
作者称 rerank 为最稳的提升,没有之一。
- 模型:bge-reranker-v2-m3
- 部署:CPU 可跑(只对 top-20 重排,非全库)
- 延迟:每 query 约 200~300ms
- 准确率:稳定 +7~8 个百分点
原理简述:
| 阶段 | 类型 | 特点 |
|---|---|---|
| 向量检索 | Bi-encoder(双编码器) | 快,但 Q 与文档分别编码再算相似度,精度有限 |
| Rerank | Cross-encoder(交叉编码器) | Q 与每个文档拼接后推理,可见交互信息,精度更高 |
推荐流水线:
1
向量检索 top-20 → rerank → 取 top-5 → 送大模型生成
- top-10 太少,排名第 10~20 的好文档会漏;
- top-30 太多,噪声跟进来了。
8. 混合检索:锦上添花
向量检索 + BM25,提升不大但稳定、零额外模型成本。
- Milvus、Qdrant 等原生支持混合检索;
- 作者用 pgvector 时,BM25 部分用 PostgreSQL 全文检索自实现。
分数融合权重需自测(与数据分布强相关)。作者项目在向量和 BM25 各自归一化后加权,向量侧权重约 0.6 量级——勿直接抄数值,应在自有数据上 A/B。
9. Prompt 工程:压幻觉
检索到的 5 条文档如何喂给大模型,对效果影响很大。
| 阶段 | 做法 | 问题 |
|---|---|---|
| 初期 | 简单拼接:「请根据以下参考资料回答问题:[文档1][文档2]…」 | 易幻觉、少引用 |
| 改进 | 结构化 prompt:标明来源与编号;要求引用来源;无相关信息时明确说「知识库中没有找到」,禁止编造 | 幻觉率 15% → 5% 以下 |
小技巧:在 prompt 中加「请优先使用排名靠前的文档中的信息」。Rerank 后 top-1 通常最相关,但大模型有时偏向后面更「通用、好答」的段落。
10. 小结与对照清单
10.1 一句话
零微调把 RAG 从 50% 拉到 88%:先把数据、分块、检索链路做扎实,再靠 query 改写、分库、rerank、混合检索、prompt 逐级加码;检索质量决定上限。
10.2 落地检查清单
| 检查项 | 是否做到 |
|---|---|
| 扫描件高精度 OCR + 关键页抽检 | ☐ |
| 表格独立结构化入库 | ☐ |
| 文档版本去重 / 只保留最新 | ☐ |
| 按条款/章节分块,避免硬切断语义 | ☐ |
| 领域术语 query 改写 | ☐ |
| 分库或 metadata 过滤 | ☐ |
| top-20 → rerank → top-5 | ☐ |
| 向量 + BM25 混合(可选) | ☐ |
| 结构化 prompt + 无则拒答 + 优先靠前文档 | ☐ |
10.3 延伸阅读
| 资源 | 说明 |
|---|---|
| 原知乎回答 | 本文整理来源 |
| RAG 天花板在检索 | 作者同系列:为何优化后仍上不去 |