RAG知识图谱简介
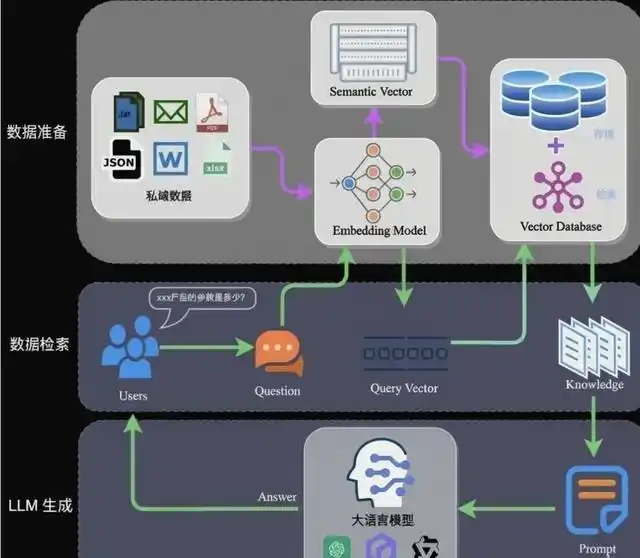
RAG知识图谱简介
一、什么是知识图谱
1.1 基本定义
知识图谱(Knowledge Graph) 是一种以图结构表示知识的方法,通过实体(Entity)- 关系(Relation)- 属性(Attribute) 三元组形式,将现实世界的对象及其关联关系进行结构化建模。
1.2 核心特征
- 结构化表达:以实体-关系-属性 (ERA) 结构化建模,而非纯文本段落
- 多跳关联:天然支持沿关系路径进行多跳推理和查询
- 语义约束:通过类型、关系约束进行精准过滤,减少语义偏移
- 可追溯性:节点/边挂接来源信息,支持审计与回滚
多跳关联示例:用户问”华为发布的操作系统在哪一年推出?” → 图上可沿路径 (华为) -[发布]-> (鸿蒙系统) -[发布时间]-> (2020年),无需长文本检索即可直接拼接答案线索。
文档引用示例:业务文档中常见“详见附件××”的表述,可在图中建模为 (文档) -[包含/引用]-> (附件);当查询“附件××的要求是什么”时,可沿此关系直接定位到附件节点及其内容,而不必全文检索。
语义约束示例:查询”位于上海的证券交易所”时,图查询可限定节点类型=”组织机构”、位置属性包含”上海”,减少文本相似度误匹配(如把”证券交易所”误解为”交易软件”)。
二、知识图谱的基本组成
扩展:史上最大规模1.4亿中文知识图谱-github.com/ownthink/KnowledgeGraphData-知识图谱数据结构
2.1 节点(实体)
定义:现实世界的对象(人/机构/产品/事件等),通常包含类型与属性。
- 类型:在本体/模式中声明实体类型(如组织机构、人工制品、位置、概念、方法、自然物品、事件、内容、数据、人物角色、未知等),可用于可视化着色与查询过滤
- 属性:描述实体的键值对(如”成立时间”“注册地”“版本号”)
- 识别方式:NER + 实体链接(EL),利用别名词典、embedding 相似度、规则校验
- 创建过程:抽取后生成节点,写入图数据库,并绑定来源文档/段落 ID 以便回溯
2.2 关系(边)
定义:实体间的语义联系(如”隶属”“采购”“依赖”“作用于”),可携带方向与属性(时间、权重、置信度等)。
- 识别方式:关系抽取(RE)、事件抽取,或规则/模板匹配;大模型可辅助生成候选,再做置信度过滤
- 创建过程:对齐起点/终点实体后生成边,附带来源、时间戳、置信度,必要时人工校验
2.3 属性
定义:描述实体或关系的键值对(如”成立时间”“注册地”“版本号”“发生时间”)。
- 识别方式:从结构化字段或信息抽取中提取;做类型校验(日期/数值/枚举)
- 创建过程:在写入节点/边时填充,保存来源与校验状态
2.4 本体/模式
定义:领域内的类型体系与约束集合,是图谱的一致性”蓝图”。
- 设计步骤:梳理业务实体/关系清单 → 定义字段与约束 → 约定命名、主键与别名策略 → 版本化管理
- 作用:指导抽取、存储、校验与查询;也是多团队协作的契约
2.5 来源与溯源
节点/边需挂接来源文档、段落或页面 URL,便于审计与回滚。
2.6 质量与消歧
通过别名表、唯一键、embedding 相似度 + 规则阈值 + 人工抽检,持续治理。
三、如何从文本构建知识图谱
扩展:医疗知识图谱构建-github.com/liuhuanyong/QASystemOnMedicalKG-业务驱动的知识图谱构建框架
3.1 构建流程
典型流水线:
1
2
3
4
5
6
7
8
9
10
原始文档/数据
→ 预处理(清洗、分段、去噪、分句)
→ 实体识别(NER:命名实体识别,找出人名/机构/地点/产品等)
→ 实体链接/消歧(EL:实体链接,alias 词表 + embedding 相似度 + 规则阈值 + 人工抽检,将文本片段对齐到具体实体节点)
→ 关系抽取/事件抽取(RE/EE:关系/事件抽取,识别"谁-与-谁-以何种关系/事件相连",可用模型/LLM/模板)
→ 本体校验(类型约束、必填属性、基数检查)
→ 置信度过滤与人工审阅(可选,边界样本人工确认)
→ 入图写入(节点/边,附来源文档/段落/时间戳/置信度)
→ 索引构建(图索引 + 向量索引 + 关键词倒排)
→ 监控与回滚(质量指标、版本/备份、审计溯源)
3.2 是否使用大模型
- 大模型并非必需,但在中文/开放域抽取、长尾别名、复杂关系识别上,LLM 能显著提升召回与质量;同时会带来成本与一致性挑战
- 轻量方案:传统 NER/RE + 规则 + 词表/alias + embedding 消歧;适合结构化/半结构化、高一致性场景
- 混合方案:LLM 生成候选 + 规则/embedding 复核 + 人工抽检;适合开放域、弱结构、多别名场景
四、核心技术原理详解
扩展:知识图谱-概念与技术 复旦大学 肖仰华-github.com/tywee/knowledge-graph-关系抽取概述
4.1 NER(Named Entity Recognition,命名实体识别)
定义:从文本中标注实体片段及类型。
- 常用技术:序列标注(BiLSTM-CRF、BERT-CRF)、LLM 提示抽取、规则/词典
- 示例:”上海证券交易所位于浦东” → 抽出 “上海证券交易所/组织机构”,”浦东/位置”
4.2 EL(Entity Linking,实体链接/消歧)
定义:将已识别的实体片段对齐到知识库中的具体实体节点。
- 常用技术:候选生成(别名/倒排/向量召回)→ 候选打分(embedding 相似度 + 规则/特征)→ 选最优;必要时人工抽检
- 示例:”苹果” → 根据上下文判断是 “Apple Inc.”(公司)而不是 “苹果/水果”
4.3 RE(Relation Extraction,关系抽取)
定义:识别实体之间的语义关系,产出三元组 (头实体, 关系, 尾实体)。
- 常用技术:依存/句法特征 + 深度模型;LLM 结构化输出;模板/规则在高精场景使用
- 示例:”华为发布了鸿蒙系统” → (华为, 发布, 鸿蒙系统)
4.4 EE(Event Extraction,事件抽取)
定义:识别事件及其论元/角色(主体、客体、时间、地点等)。
- 常用技术:触发词识别 + 论元填充;可用模型、LLM 或规则模板
- 示例:”2020年华为发布鸿蒙系统” → 事件=发布;论元:时间=2020年,主体=华为,对象=鸿蒙系统
4.5 辅助组件
- 分词工具(如结巴分词 jieba):将中文文本切分成词语序列,是NER/RE等任务的前置预处理步骤。结巴分词本身不做实体/关系抽取,但为后续任务提供词语边界和词性标注(POS)等基础信息。例如:”上海证券交易所位于浦东” → 分词为 [“上海”, “证券”, “交易所”, “位于”, “浦东”],NER模型在此基础上识别出完整实体”上海证券交易所/组织机构”
- 别名/词表:支撑候选生成与消歧
- Embedding 相似度:长尾匹配、别名发现、候选排序
- 规则/模板:硬约束(类型/格式/时间数值校验)与高精句式
- 置信度与审阅:低置信度样本进入人工审核闭环
五、知识图谱 vs 普通知识库
扩展:GraphRAG + DeepSearch 实现与问答系统(Agent)构建-github.com/1517005260/graph-rag-agent-更复杂的产品化效果-包含轨迹追踪图谱推理过程
5.1 普通知识库的特点
- 以文档/段落为基本单位,偏”段落检索 + 大模型生成”
- 关系弱,结构化程度低
- 召回常依赖向量相似度
5.2 知识图谱的特点
- 以实体-关系-属性 (ERA) 结构化建模
- 天然支持多跳关联和语义约束
- 可与文本片段双索引(图索引 + 向量索引)协同工作
5.3 对比分析
优势:
- 结构化表达:关系明确,可表达复杂语义和路径检索
- 可解释性:节点/边及路径可视化,便于溯源
- 精准检索:实体、关系过滤结合向量召回,提升精度
- 复杂查询:天然支持图查询语言(Cypher/Gremlin)和多跳问答
劣势:
- 构建成本高:实体抽取、关系抽取、对齐、清洗、版本管理需要额外流程
- 维护复杂:别名/消歧、数据漂移、模式演进需要持续运维
- 覆盖度权衡:低噪高质 vs 覆盖面,需要取舍;过度结构化可能丢失细节
5.4 普通知识库实现多跳查询的方案
普通知识库虽然缺乏知识图谱的结构化优势,但可以通过以下方案实现类似的多跳查询能力:
1. 数据治理方案
- 文档结构增强:在”详见”、”参照”、”参考”等文档跳转关键词后面增加章节链接锚点,建立文档间的显式引用关系。例如:”详见附件A” → 自动添加锚点链接到”附件A”章节。
- 章节语义增强:在跳转的附件章节中,修改章节名称,增强语义描述。例如:将”附件A”改为”附件A:数据安全管理办法”,提升向量检索的匹配精度。
- 局限性:需要大量人工标注和文档处理工作,耗费工时;对于已有大量文档的场景,改造成本较高。
2. 工作流节点额外抽取
- 多轮迭代检索:在获取第一阶段检索结果后,增加额外处理节点,提取检索结果中的”详见”、”参考”、”依据”等关键字及其关联内容。
- 关联内容检索:根据提取的关键字,再次在知识库中查找被引用的文档或章节,并将结果拼接到工作流回复中。
- 递归深度控制:设置最大递归深度(如2-3跳),避免无限循环和性能问题。
- 局限性:需要适配开发工作流节点,增加系统复杂度;在海量文本中,关键字提取可能不精准,导致误召回或漏召回。
3. 提示工程增强 在 LLM 的 prompt 中明确要求进行多跳推理,引导模型识别文档间的引用关系并主动查找相关内容。
- 局限性:不可控,受限于大模型本身的理解能力。
六、适用场景与决策指南
6.1 典型适用场景
- 实体/关系密集领域:金融、医疗、法律、供应链、政企知识库
- 需要多跳逻辑的问答:合规审查、风控溯源、因果/依赖分析
- 需要可解释与可追溯:审计、合规、决策支持
- 需要消歧/别名管理:人名地名产品名混淆场景
6.2 不适合或性价比低的场景
- 需求以简单 FAQ/关键词检索为主
- 数据规模小且关系简单
- 更新极端频繁且对一致性要求低的临时知识
- 团队缺少长期图谱运维能力
6.3 何时不必使用图
- 数据规模小、关系简单、主要是纯文本 FAQ
- 构建/运维资源有限,或对可解释性需求不高
- 更新频率极高且容错成本低的临时知识
七、LightRAG 查询模式详解
LightRAG 提供了多种查询模式,用户可以通过在查询前添加前缀来选择不同的检索和生成策略。默认模式为 hybrid(混合模式)。
7.1 核心查询模式
/local(本地模式)
- 作用:基于查询中的实体,在知识图谱中构建局部子图(Local Graph),仅检索与查询实体直接相关的节点和关系。
- 特点:
- 聚焦于查询相关的局部区域,检索范围较小
- 适合精确查询,响应速度快
- 可能遗漏间接相关的信息
- 适用场景:查询目标明确,需要快速获取直接相关的实体和关系信息
/global(全局模式)
- 作用:基于查询语义,在全局知识图谱中进行检索,考虑所有可能的实体和关系路径。
- 特点:
- 检索范围广,可能发现间接关联
- 适合复杂推理和多跳查询
- 计算成本较高,可能引入噪声
- 适用场景:需要多跳推理、发现间接关联、探索性查询
/hybrid(混合模式,默认)
- 作用:结合本地模式和全局模式的优势,先进行局部检索,再基于结果进行全局扩展。
- 特点:
- 平衡精度和召回率
- 兼顾直接关联和间接关联
- 是大多数场景的推荐模式
- 适用场景:通用查询场景,需要平衡准确性和完整性
/naive(朴素模式)
- 作用:不使用知识图谱结构,仅基于向量相似度进行文本检索,类似传统 RAG。
- 特点:
- 不利用图结构信息
- 依赖纯语义相似度匹配
- 计算简单,但可能缺乏结构化推理能力
- 适用场景:知识图谱未构建或质量较低时,作为降级方案
/mix(混合策略模式)
- 作用:采用混合检索策略,可能结合多种检索方法(图检索 + 向量检索 + 关键词检索)。
- 特点:
- 综合利用多种检索手段
- 提升召回率和鲁棒性
- 计算复杂度较高
- 适用场景:对召回率要求高,需要多种检索手段互补的场景
7.2 特殊模式
/bypass(绕过模式)
- 作用:完全绕过 LightRAG 的检索流程,直接将查询和聊天历史传递给底层 LLM,不进行任何知识库检索。
- 特点:
- 不进行知识库检索
- 仅依赖 LLM 的预训练知识
- 可用于测试 LLM 能力或处理非知识库相关的问题
- 适用场景:测试 LLM 能力、处理通用对话、不需要知识库检索的场景
- 注意:如果使用 Open WebUI 作为前端,可以直接切换到普通 LLM 模型,无需使用此前缀
/context(上下文模式)
- 作用:不生成最终答案,仅返回为 LLM 准备的上下文信息(检索到的相关文档片段或图路径)。
- 特点:
- 仅返回检索结果,不调用 LLM 生成
- 可用于检查检索质量
- 支持自定义上下文处理
- 适用场景:调试检索效果、自定义上下文处理逻辑、分析检索结果
7.3 上下文版本模式
以下模式是核心查询模式的上下文版本,仅返回上下文信息,不生成最终答案:
- /localcontext:本地模式的上下文版本,返回局部子图检索结果
- /globalcontext:全局模式的上下文版本,返回全局检索结果
- /hybridcontext:混合模式的上下文版本,返回混合检索结果
- /naivecontext:朴素模式的上下文版本,返回向量检索结果
- /mixcontext:混合策略模式的上下文版本,返回混合检索结果
7.4 使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 默认混合模式查询
What's LightRAG?
# 使用本地模式
/local 华为发布了哪些产品?
# 使用全局模式
/global 哪些公司与华为有合作关系?
# 使用混合策略模式
/mix 数据安全管理办法的具体要求是什么?
# 绕过检索,直接使用LLM
/bypass 解释一下量子计算的基本原理
# 仅获取上下文
/context 华为的合作伙伴有哪些?
7.5 模式选择建议
| 查询类型 | 推荐模式 | 说明 |
|---|---|---|
| 精确实体查询 | /local | 快速获取直接关联信息 |
| 多跳推理查询 | /global | 发现间接关联和路径 |
| 通用查询 | /hybrid(默认) | 平衡精度和召回率 |
| 简单语义匹配 | /naive | 降级方案或简单场景 |
| 高召回率需求 | /mix | 多种检索手段互补 |
| 调试检索效果 | /context系列 | 检查检索质量 |
| 非知识库问题 | /bypass | 直接使用LLM |