RAG知识库常用策略和配置
RAG知识库常用策略和配置
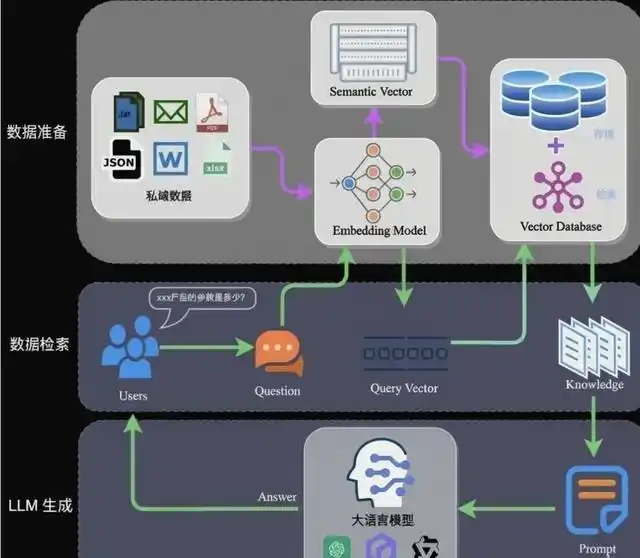
本文梳理 RAG 知识库搭建中的常用策略与配置,涵盖问题路由、检索方式、分块设计、重排取舍以及大模型参数调优,便于按场景选型与落地调优。
目录
一、策略类
整体优化思路:倒推。 基于发生问题的路径上的每个工作流节点环节,逐个倒推分析优化的可能性。例如:若回答质量不佳,可沿「用户问题 → 问题优化 → 检索 → 引用截断/重排 → 大模型对话」这条链路,从出问题的环节往前排查,在对应节点上应用下文策略进行调优。
1.1 问题路由 + 知识库子库划分
思路:不每次都检索全量文档,而是先对问题进行路由分类,再在对应的知识库子库中检索,缩小检索范围,提升精准度。
适用场景:
- 文档数量多、类型杂(政策、产品、FAQ、附件等混在一起)
- 不同业务线或主题的文档边界清晰
- 用户问题通常能归到某一类(如「问政策」「问产品」「问流程」)
实现要点:
- 路由分类:用规则(关键词、正则)或小模型/分类器,将问题映射到预定义的类别(如「政策法规」「产品手册」「常见问题」)。
- 子库划分:按业务或主题拆成多个知识库,路由结果决定检索哪个子库。
- 兜底策略:若路由不确定,可检索「通用库」或做多子库并行检索后合并。
效果:文档越多,全量检索噪音越大;子库划分后,检索范围缩小,命中更精准,且可针对不同子库采用不同分块和检索策略。
1.2 检索策略的使用
常见检索方式有三种,需按场景选择:
| 检索方式 | 适用场景 | 特点与注意点 |
|---|---|---|
| 全文检索 | 政策法规、条款、标准等需精准匹配 | 基于关键词/BM25,对专有名词、条款编号、法条引用等命中准确;对同义改写、口语化表述不敏感 |
| 语义检索 | 发散性讨论、概念解释、经验总结 | 基于向量相似度,对语义相近的表述都能命中;对精确字面匹配较弱,可能引入语义偏移 |
| 全文 + 语义 | 既有精准要求又有语义理解 | 混合检索,需调比例(如 0.3 全文 + 0.7 语义);比例过偏全文易漏语义,过偏语义易漏关键词 |
选型建议:
- 政策法规、合同条款:优先全文或「全文为主、语义为辅」。
- 产品介绍、FAQ、经验分享:优先语义或「语义为主、全文为辅」。
- 混合场景:先小样本测试,再调全文/语义权重,观察命中率与误召回。
1.3 是否开启问题优化
问题优化:在检索前,用大模型对用户原始问题进行改写、扩展或澄清,以期提升检索效果。
代价:多一次大模型调用,增加 token 消耗和处理时延。
适用场景:
| 场景 | 建议 | 说明 |
|---|---|---|
| 发散性讨论、开放问答 | 可开启 | 用户表述模糊、口语化时,优化后检索更稳 |
| 政策法规、条款、精准检索 | 不建议开启 | 容易引入理解偏差,改写后可能偏离原意,影响精准度 |
| 短问题、关键词明确 | 可不开启 | 直接检索往往已够用 |
| 检索不精准 + 依赖多轮补全 | 强烈建议开启 | 检索效果不理想、已配置历史问题引用但受限于对话上下文过多而效果不佳、且极度依赖多轮对话来补全问题信息时,开启问题优化可提高问题质量,从而提升检索精准度 |
实践建议:先关闭问题优化,在测试集上评估检索效果;若发现因表述方式导致漏检,再尝试开启并对比效果与成本。
1.4 知识库分块
分块质量直接影响检索命中率,需根据文档特点选择策略。
按 QA 问答对分块(最精准)
- 做法:将文档中的「问题-答案」对作为独立块,块内容即一问一答。
- 适用:FAQ、产品 Q&A、标准问答等结构化内容。
- 优点:检索命中后,块内即完整答案,无需再拼接,引用质量高。
按块大小划分
- 做法:按固定 token 数或字符数切块,可设置重叠(overlap)避免语义断裂。
- 常见配置:块大小 300~800 token,重叠 50~100 token;具体需结合文档类型调优。
- 块大小影响:
- 过小:上下文不足,语义不完整,易漏关键信息。
- 过大:单块包含过多内容,检索时容易带出无关段落,且单块 token 占用多,影响可引用块数。
- 建议:政策法规可偏大(500~800),FAQ 可偏小(200~400),先小样本测试再定。
按指定分隔符分块
- 做法:以标题、段落、章节标记(如
##、---)或自定义分隔符为边界切块。 - 优点:可手动在文档中加入分隔符做标记,使分块更贴合业务结构(如按条款、按章节)。
- 实践:对重要文档,可在 Word/Markdown 中预先插入分隔符,再导入知识库,提升分块质量。
分块策略小结:优先考虑文档结构;有明确 QA 的用 QA 对,无结构的用「块大小 + 分隔符」组合,并配合重叠避免断句。
1.5 文档格式转换
表格格式比章节格式更便于检索和大模型理解。 可使用 Python 脚本或 MCP 工具,将 Word 文档内容结构化提取为竖式表格形式的 Markdown 文件,Word 文档每个章节对应表格中的一行,提升检索命中准确度。提取后的 Markdown 再导入知识库,按行或按块分块,检索时单行即完整语义单元,减少跨章节噪音。
1.6 知识库检索效果测试
原则:先验证检索效果,再调分块和策略,避免盲目调参。
推荐流程:
- 在测试/数据集页面直接测检索:输入典型问题,查看 topN 检索结果是否包含期望内容。
- 效果不好时的排查顺序:
- 索引内容:检查分块后的索引内容是否合理,有无截断、乱码或无关信息混入。
- 分块边界:若期望内容被拆到两个块中,可调整块大小、重叠或分隔符,使关键信息完整落在同一块。
- 检索策略:尝试切换全文/语义/混合,或调整混合比例。
- 效果达标后再接入大模型:检索稳定后,再优化提示词和生成参数。
1.7 何时使用向量重排
重排:在首轮检索得到 topN 后,用更精细的模型(如 Cross-Encoder)对候选块重新打分排序,提升相关块排名。
判断流程:
- 第一步检索 topN 能否找到期望内容?
- 找不到:优先调整分块质量、检索策略或子库划分,使内容能被检索到;重排无法「变无为有」。
- 找到了,但排名靠后:可引入重排,把相关块提到前面,增加被大模型引用的概率。
重排的代价:增加一次重排模型推理,拉长整体耗时;需权衡延迟与效果。
1.8 向量重排的替代实现
若不想引入独立重排模型,可用以下替代方案实现类似效果。除本节的「子库拆分 + 引用合并」外,1.9 知识库引用截断 也是常用替代之一,可单独选用或组合使用。
方案一:子库拆分 + 引用合并
思路:
- 知识库拆成多个子库:按主题或粒度拆成 2 个及以上子库。
- 工作流中并行检索:对同一问题,在各子库中分别检索,得到多组结果。
- 引用合并节点:将多组结果送入引用合并节点,利用节点内置的相关性排序能力,对合并后的块重新排序,并过滤低相关性内容。
优点:无需单独部署重排模型,利用现有工作流能力即可实现排序优化和噪音过滤;适合对延迟敏感、又希望提升引用质量的场景。
注意:子库划分需合理,避免重复内容过多导致合并后冗余;合并策略(如去重、截断)需根据实际效果微调。
1.9 知识库引用截断
本策略也属于向量重排的替代实现之一,与 1.8 子库拆分 + 引用合并 并列,通过代码节点对引用做筛选,无需引入重排模型。
适用场景:大模型对话输出中混入了不想要的内容,且这些内容来自非期望文档(如相近但不相关的文档被一并检索出来,污染了回答)。
思路:在检索节点之后、大模型对话引用之前,增加一个代码节点,从上游获取检索出的知识库引用数据,做筛选后再传给大模型。
方案 1:只取最重要的部分
- 做法:只保留 topN 或 top1 的引用,其余丢弃。
- 适用:检索结果中排名靠前的块已足够回答,后续块多为噪音。
- 实现:按相关性分数或顺序截取前 N 条引用即可。
方案 2:只取单一文档的内容
- 做法:避免多文档内容混在一起污染回答,只保留「与 top1 同文档」的引用。
- 步骤:
- 取 top1 引用,解析出引用的文档名称(或文档 ID)。
- 遍历引用数组,剔除非同一文档的引用。
- 将同一文档的引用块合并或按序拼接,作为最终传给大模型的引用内容。
- 适用:多个相近文档被检索到时,希望回答只基于「最相关的那一份文档」,避免其他文档干扰。
- 效果:同一文档的多个块可完整保留,上下文更连贯;其他文档的块被过滤,减少误引用。
实践建议:若发现回答中频繁出现非期望文档的内容,可先尝试方案 1 缩小引用范围;若仍存在多文档混杂问题,再采用方案 2 做文档级过滤。
二、配置类
2.1 知识库引用上限
知识库引用上限决定传入大模型上下文的引用内容总量(块数或 token 数),需在「引用完整性」与「上下文占用、延迟、成本」之间权衡。
- 上限过小:引用内容容易被截断,关键信息丢失,影响回答准确性。
- 上限过大:易超模型本身上下文长度(如 4K、8K、32K、128K),且上下文越长,处理越慢、成本越高。
- 建议:根据「系统提示 + 用户问题 + 知识库引用」的实际长度预留余量;若引用块多,可适当提高上限,但需监控延迟与成本;也可配合 1.9 知识库引用截断 做引用筛选,在保证关键信息的前提下控制引用量。
2.2 大模型对话参数:温度
温度(temperature):控制生成的随机性,影响回答的稳定性和创造性。
| 场景 | 建议范围 | 说明 |
|---|---|---|
| 精准回答、政策法规、数据引用 | 0.1~0.3 | 低温度,输出更确定,减少幻觉和随意发挥 |
| 发散创作、头脑风暴、开放讨论 | 0.6~0.9 | 高温度,输出更多样,适合创意类任务 |
| 通用问答 | 0.4~0.6 | 中等温度,平衡准确性与自然度 |
实践:先按场景选定区间,再在测试集上微调;若发现回答过于死板可略升,过于随意可略降。
小结
| 类别 | 要点 |
|---|---|
| 策略 | 问题路由 + 子库划分缩小检索范围;全文/语义/混合按场景选;问题优化慎用于精准检索;分块按文档特点选 QA/块大小/分隔符;先测检索再调参;重排用于「能命中但排名靠后」;可用子库+合并节点替代重排;引用截断(topN/单文档过滤)减少非期望文档污染 |
| 配置 | 知识库引用上限需兼顾引用完整性与上下文占用;温度按精准/发散场景调节 |
按上述策略与配置逐项落地,并结合检索测试持续迭代,可显著提升 RAG 知识库的检索质量与回答效果。